Everyone (including new parents at 3am) should have their own AI agent.
Two things happened to me at the end of 2025. I became a proud father. And I switched to a new team at work and started working on building AI agents. Naturally, I wanted to combine both into one side project, not only making my life easier as a father (hopefully), but also helping me learn more about building AI agents.
When you have a newborn, your life becomes a series of data points: how many milliliters of milk, which side for breastfeeding, how many wet diapers, how many minutes of sleep, what time was the last feeding. The kraamzorg asks you these questions at every visit. Your wife asks you at every handoff. You ask yourself at 3am when you can't remember if the last bottle was 30 minutes ago or 3 hours ago.
Of course, there are apps for this. I tried Huckleberry, which is one of the most popular baby tracking apps. But the core features are basic. You just log events (feedings, diapers, sleep) and see visualizations. Tap a category, fill in a form, submit. It works, but it felt like exactly the kind of thing an AI agent could replace. And with an LLM in the loop, the logging interface could be much more casual - no rigid forms, just natural language. You could text "120ml at 2pm" in a family group chat and be done with it.
So I decided to build an AI agent that my whole family could use, which is a Telegram bot where anyone could send a natural language message and have it logged into a PostgreSQL database automatically (remember I set up a database for my DNA Department in a previous post?). No forms, no dropdowns, no app to learn. Just text what happened, in Chinese or English, and the agent handles the rest.
The project: a Telegram bot baby tracker #
The idea was simple. A family Telegram group where anyone (my wife, my parents, my in-laws) could log baby activities by just sending a message. The agent would:
- Parse natural language input in Chinese or English
- Log the data into my self-hosted PostgreSQL tables (feedings, diapers, sleep, supplements, growth, temperature)
- Respond with a confirmation and a 24-hour summary
- Answer ad-hoc questions like "how much milk did the baby drink today?" or "show me a chart of sleep patterns this week"
The database schema covers eight activity types: bottle feedings, breastfeeding, diapers, sleep, pumping, supplements, growth measurements, and temperature readings. All tables live in a schema with timestamps and a field tracking who sent the message.
Framework choice: Claude Agent SDK #
I'm a Claude Max subscriber and Claude Code power user, so the Claude Agent SDK was the natural choice for building this agent. There was one concern: at the time, the SDK wasn't fully open-sourced, which made it harder to understand the internals.
But I found learn-claude-code, a community project that reverse-engineered the core concepts behind Claude Code's agent architecture. Reading through that codebase turned out to be one of the most important things I did for this project, not only for the baby tracker specifically, but also for understanding what makes something truly agentic.
Version 1: the non-agentic agent #
Here's the ironic thing. I used Claude Code, arguably the most powerful agentic coding tool available, to build my first version of the baby tracker. And it produced the most non-agentic code ever.
The first version had nine separate Python tool files, each one a hardcoded function with explicit validation logic, explicit database operations, and explicit response formatting:
bottle_feeding.pybreastfeeding.pydiaper.pysleep.pypumping.pygrowth.pysupplement.pytemperature.pysummary.py+utils.py
Each tool had a rigid function signature: log_bottle_feeding(volume_ml=100, type="formula"). Each tool manually validated inputs, manually converted timezones, manually formatted responses, and manually calculated 24-hour summaries. The agent's job was reduced to: parse the user's message, figure out which specific pre-defined function to call, fill in the parameters, return the result.
It worked. But it was not there yet. Want to add a new tracking category? Write another file. Want to change how summaries are calculated? Edit every single tool file. Want the agent to generate a chart? Sorry, there's no tool for that.
The revelation: what makes something truly agentic? #
Then I read through the learn-claude-code codebase, and something clicked.
Claude Code doesn't have a fix_bug() tool or a refactor_function() tool or a write_test() tool. It has primitive, general-purpose tools:
- Read — read a file
- Write — write a file
- Glob — find files by pattern
- Grep — search file contents
That's it. You give it capabilities, not purposes. The agent figures out what steps to take, what code to write, what commands to run, all in a while loop. You don't define a workflow. Instead you define a toolbox. The magic is in the ReAct/CodeAct-style agent while loop: the model observes the environment, reasons about what to do, takes an action, observes the result, and repeats, until the purpose is achieved.
This was the fundamental mistake in my Version 1. I had defined purposes (log a bottle feeding, query diapers, calculate summaries) instead of capabilities (read files, run code, query a database). I had built an explicit workflow, not an agent.
Version 2: the truly agentic approach #
Armed with this insight, I rewrote the entire thing. Here's the core of the new agent configuration:
builtin_tools = ["Bash", "Read", "Glob", "Grep"]Four tools. That's all. The agent gets:
- A system prompt explaining what it is (a baby tracker for family use)
- A
.claude/CLAUDE.mdfile documenting the database schema and connection code - Four built-in tools to interact with the environment
When a user sends "120ml formula", the agent doesn't call a specific log_bottle_feeding() function. Instead, it:
- Reads
.claude/CLAUDE.mdto understand the database schema - Writes Python code to insert a row into my
bottle_feedingstable - Runs the code via Bash
- Queries the database for 24-hour totals
- Formats a response
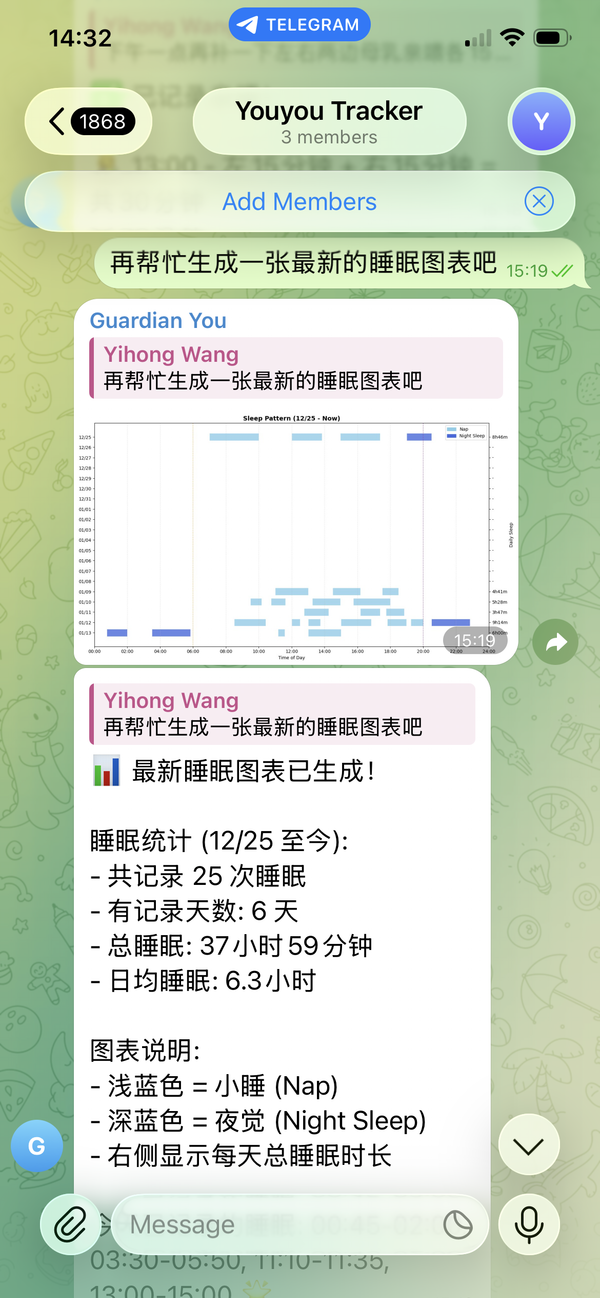
When a user asks "show me a chart of feeding patterns this week", the agent doesn't return an error saying "no chart tool available." Instead, it:
- Writes Python code using matplotlib to query the database and generate a chart
- Saves the chart as a PNG
- Returns the image
The essence of agentic ability #
The experience crystallized a simple framework for thinking about AI agents:
Workflow approach (Version 1): You define the steps. The LLM fills in the blanks within each step. You are the architect, the model is the laborer.
Agent approach (Version 2): You define the capabilities. The LLM decides the steps. You provide the toolbox, the model is the architect.
The irony still feels funny to me. The most agentic coding tool in the world, Claude Code, initially produced the most non-agentic code when I asked it to build an agent. I think that was on me though. It's because in my prompt, I asked it to "build a baby tracker with tools for each activity type." I described a workflow. It built a workflow. The tool faithfully implemented my non-agentic design.
The lesson: give the agent narrow, purpose-built tools, and you get a narrow, purpose-built system. Give it general-purpose capabilities and good documentation, and you get something that can handle anything you throw at it, including things you never anticipated.
Is software dead? #
Building this agent made me think about the "software is dead" narrative that's been going around. The idea is that AI agents will replace traditional SaaS products. When Claude launched Cowork and made plugins available for industries like legal, the stock market dipped because people started doubting the future of SaaS. And honestly, my experience building this baby tracker is a data point in that direction. Huckleberry is a well-designed app with a team behind it, and I replaced its core functionality with a weekend project.
I've seen this pattern in other areas of my life too. Last year when I moved to a new house, I chose Apple HomeKit over Home Assistant because I thought maintaining Home Assistant would be too time-consuming. If I were making that choice today, it would be a no-brainer. Home Assistant all the way. With tools like Claude Code, the "maintenance burden" of self-hosted, open-source software has dropped dramatically. The trade-off has shifted.
But I don't think the story is that simple. There's one thing Huckleberry has that my agent doesn't: a data flywheel. Huckleberry has data from thousands of babies — their sleep patterns, their feeding schedules, their growth curves. They can train algorithms to predict the optimal nap time for your specific baby based on patterns from all the other babies in their dataset. My agent only has data from one baby. I can use an LLM as a common-sense sanity check ("does this sleep schedule seem normal for a 2-month-old?"), but that's not the same as a quantitative prediction model trained on real data from thousands of infants in this specific domain.
So maybe software isn't dead, but the moat has moved. The moat is no longer the UI, the forms, the basic CRUD operations. Those are replaceable by agents. The moat is the data. The flywheel that no individual user can replicate on their own.
Is the dashboard dead? #
I wrote about setting up my own Metabase dashboards as a core piece of my DNA department. Now that I have an agent that can generate any chart on demand via Telegram, do I still need them?
This is actually a classic debate in data teams: curated dashboards vs. self-service ad-hoc analysis. After living with both, I think they serve fundamentally different modes.
Dashboards are for monitoring. You open Metabase and immediately see 5-10 metrics at a glance: total milk today, diaper count, sleep hours, feeding trend this week. Your eye catches the anomaly without asking a question. It's the single source of truth for your KPIs, rendered the same way every time, instantly, for free.
Chat is for investigation. "What's the correlation between sleep duration and feeding volume this week?" or "Compare this week's feeding pattern to last week." These are questions you can't pre-build a dashboard for. The agent writes custom code, generates a one-off chart, and you ask follow-up questions. That flexibility is something no dashboard can match.
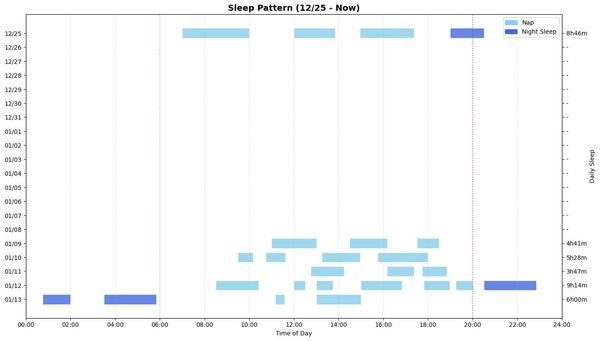
The lines do blur though. You could persist the logic for generating a specific chart as an agent skill, so it produces the same stats the same way every time, which is functionally similar to a dashboard view. But each run still costs API tokens and has latency (the agent thinks, writes code, runs it), while Metabase loads instantly. For something you check five times a day, that difference matters.
Where dashboards win: glanceability, zero latency, shared views the whole family can bookmark. Where chat wins: unlimited flexibility, follow-up questions, no maintenance when the schema changes. But both are pull interfaces, so you need to go to them. There's a third mode that neither does well: push. The agent comes to you. "The baby slept 30% less than usual today." "Feeding volume is trending down this week." A Telegram-based agent is naturally suited for this. It's already in your chat. As a next step, I'll explore how to make the agent more proactive and share with you in future.
My current take: I'll probably shift most of my ad-hoc analysis to the chat interface and keep Metabase for the persistent, at-a-glance monitoring dashboard. The agent is better for exploring; the dashboard is better for watching.
My DNA department grows #
My personal DNA department now has its first AI employee. It works the night shift. It speaks Chinese and English. It's a generalist, being so agentic that it doesn't need a dedicated script for learning a new tool — you just update the documentation and it figures out the rest by itself. What's the next agent the department might have? Stay tuned.